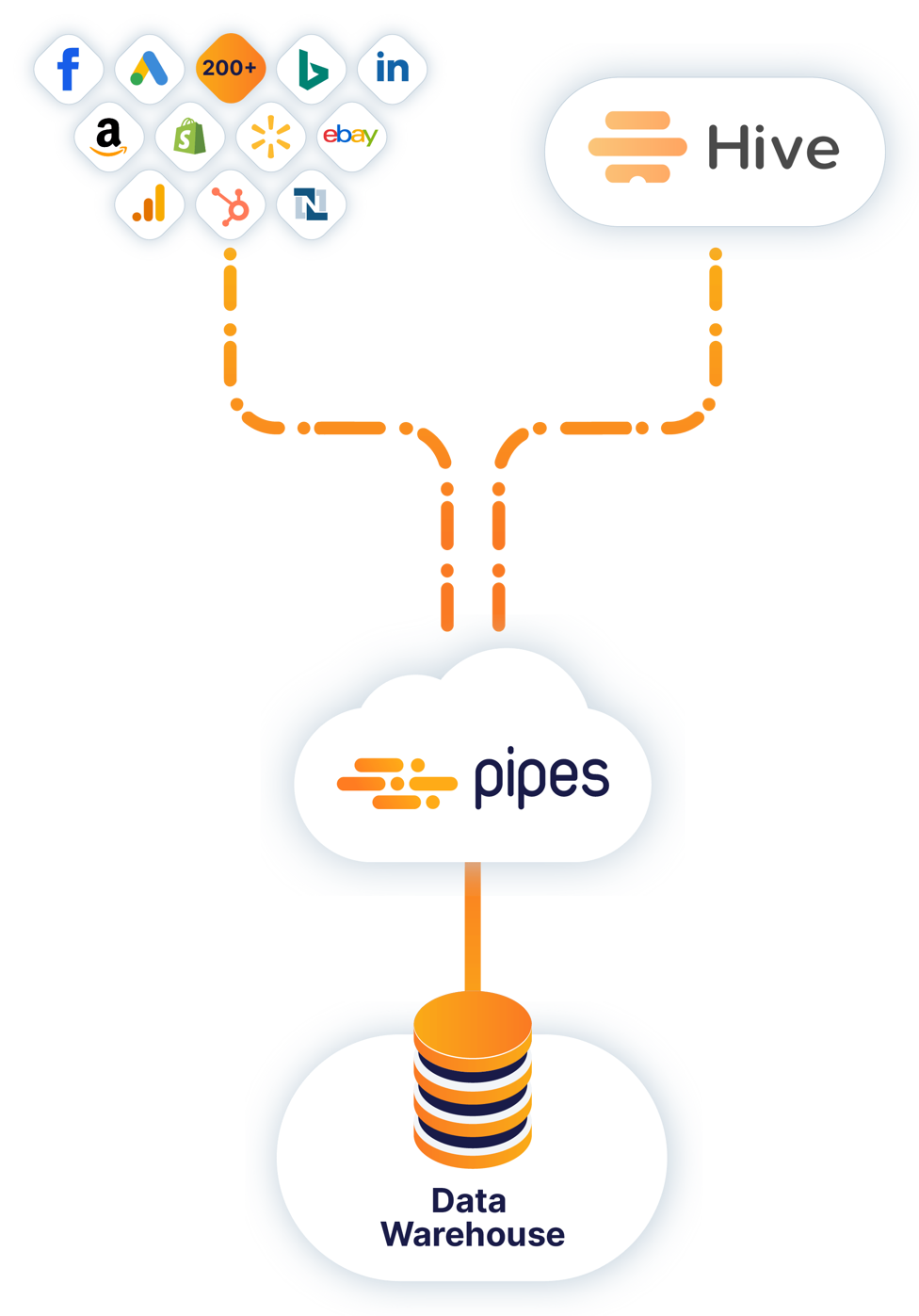
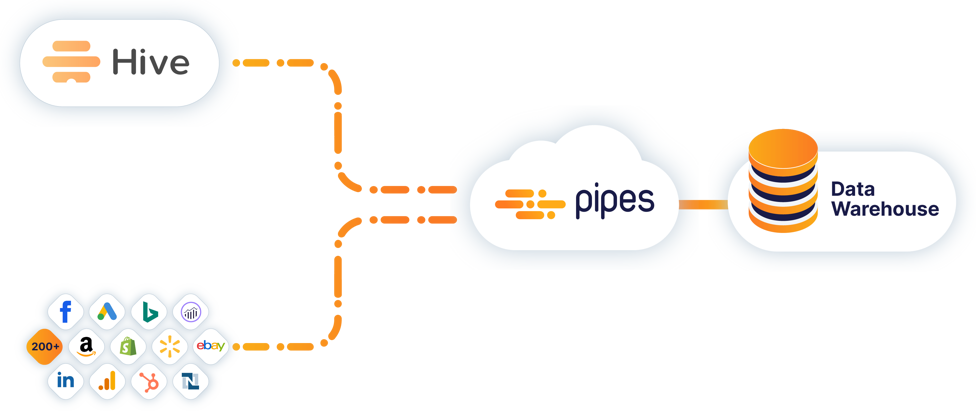
Apache Hive is a data warehouse infrastructure which provides query, data summarization, and analysis, built on top of Hadoop. The Apache Hive data warehouse software facilitates writing, reading, and managing large datasets with distributed storage using SQL. A JDBC driver and command line tool are provided to connect users to Hive.
Use Cases
Explore how you can use Pipes in different scenarios.
Learn
Learn more about Pipes with customer stories, useful blog posts and the documentation.
Customer Case Study
Boosted Commerce automates all data integration processes with Pipes Professional.
Customer Case Study
SM Nutrition saves resources and costs through a lean inventory management.
Documentation
Read through the Pipes documentation here.
Blog
Find useful guides and further informative articles in our blog.
 Customer Case Study: How Boosted Commerce automated all data processes
Customer Case Study: How Boosted Commerce automated all data processesLearn how Boosted Commerce quickly evolved into one of the world’s largest brand aggregators by automating all data integration processes with Pipes Professional